导航
- 01 流批一体
- 02 Checkpoint机制
- Unaligned Checkpoint
- Generalized Incremental
- 03 性能与效率
- 04 Table/SQL&Python API
本文是笔者对Apache Flink Meetup • 深圳站直播大会Flink1.14新特性预览的学习笔记整理,作者楠木大叔,感谢您的阅读,预计阅读时长3min。
昨天参加了Apache Flink 社区主办的Apache Flink Meetup • 深圳站直播大会(时间: 2021-08-07 13:30:00)。在直播中宋辛童,Apache Flink PMC Memeber&Commiter,阿里巴巴技术专家讲解了即将发布的Flink1.14新特性。
正好这段时间工作上有基于flink的应用和实践,故对这个部分比较感兴趣。按照国际惯例,对本次学习做了一些整理,分享给更多没有参与这次直播大会的道友。
流批一体
流批一体的背景
在业界我们观察到大数据实时化的趋势,但是目前离线处理的需求也很难被实时替代,处于会长期存在的状态。
在大数据实时和离线同时存在的状态下,以往的的流、批一体独立方案实施存在一些痛点:
- 人力成本高,如同时需要维护两套系统
- 数据链路冗余,处理的是相似的内容
- 数据口径不一致
如果流、批处系统使用不同的技术来处理,由于不同技术引擎本身的差异,会造成数据口径的不一致,数据的计算上会有一些误差,
这种无法其实对大数据分析结果会有比较大的影响。
在这样的背景之下,flink社区认定了能够同时处理实时和离线的一体化的结构是一个比较重要的趋势。
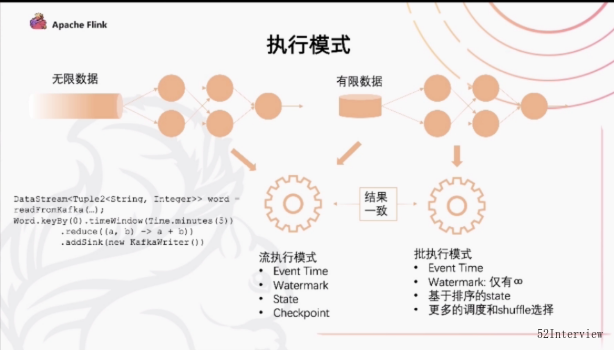
执行模式
在过去的几个版本中,Flink在流批一体方面做了很多的工作,我们到现在其实已经可以认为flink在引擎层面,在API层面,在算子的执行层面是真正地做到了流批使用同一套机制运行的。
但是在任务的具体执行模式上,其实还是有不同的两种执行模式的。
无限数据流
那么对于一个无限的数据流,是统一的采用了一种叫做流的执行模式
所谓的流的执行模式就是指我的所有的计算节点之间是通过一个pipeline 这样的边去连接的
pipeline的边就是你的上游和下游的算子的同时运行,数据随着上游的不断产出数据,下游同时地在消费这个数据,这样的一个全pipeline的执行方式,我们叫做流的执行方式
在这种模式下,我们有
- Event Time 表示你的数据是什么时候产生的
- Watermark 表示截至到目前哪个时间点之前的数据已经全部到达了
- State 维护计算的中间状态
- Checkpoint 然后依靠Checkpoint的机制 做一些容错的处理
有限数据
批的执行模式
可以当作有限的数据流来执行
- Event Time
- Watermark 仅有∞
- 基于排序数据的State
- 更多的调度和Shuffle选择
这里批的执行模式和流的执行模式最主要的区别是:
- 批的执行模式中间会有落盘的过程,任务是分段执行的,前面的任务执行完成之后会把所有的数据落盘
- 然后下游的任务菜开始调度,根据上游落盘的数据再继续往下处理,这里的容错也是依靠shuffle来进行容错的
对于有限数据集来讲,我们认为流的执行模式与批的执行模式各有各的优势:
- 对于流的执行模式来讲,它没有落盘这样的一些压力,同时它的容错是基于数据的分段
在整个无限的数据流中不断地去打点(checkpoint),然后去进行断点的恢复
- 对于批的执行模式其实是有很大的落盘压力,因为数据是由排序的 在数据计算性能上会有很大的提升
另外我的所有任务并不需要同时执行,而是可以分段地去执行。
那在容错方面,它其实是根据计算的state来进行容错,这两种各有优劣,可能要根据作业的场景来选择。
那在这种情况下,我们认为流执行模式和批执行模式对于有限数据集的处理,从长期来看都是有意义的。
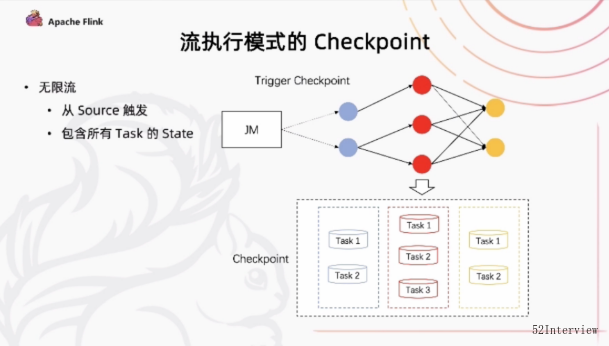
流执行模式下的Checkpoint
那我们在flink 1.14中的优化主要针对的是在流执行模式下如何去处理有限数据集?
流执行模式下,我们之前处理无限数据集跟现在处理有限数据集最大的一个区别
在于我们引入了任务可能会结束的概念
那在这种情况下也会带来一些新的问题。
比如,在流执行模式下的Checkpoint机制
对于一个无限流,它的Checkpoint由所有的Source事件去进行触发的从Source上去发一个Checkpoint Barrier,当Checkpoint
Barrier流过整个作业的时候,
我们说完成了一个Checkpoint。
同时在这一次Checkpoint中,会存储了所有任务对应的state.这是流的执行模式。
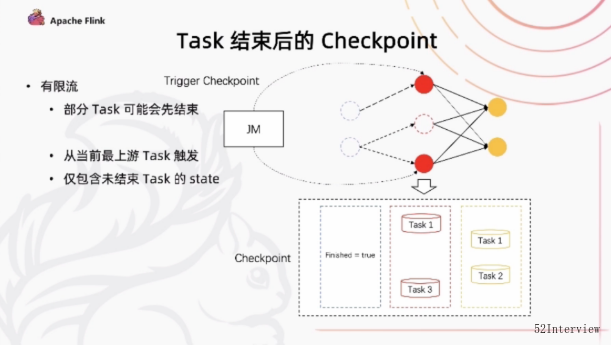
但是,对于有限流的话,我们上游的task有可处理完成之后退出,下游可能依然还在执行或者说我们在同一个state下的不同的并发,由于数据量的不一致。
可能也会出现一部分任务先结束 我们后续的作业执行过程总如何去进行checkpoint呢?
在flink 1.14 中 我们引入了一个Job manager 能够动态地根据任务的执行情况确定Checkpoint Barrier应该从哪里开始触发这样的一个机制。
同时我们在部分任务结束之后,我们后续的checkpoint当中只会保存还仍在运行的task的对应的state。
通过这种方式,我们能够让前面任务执行完成之后,后续的还能够继续的去做Checkpoint
在有限流的执行当中提供了更好的容错保障
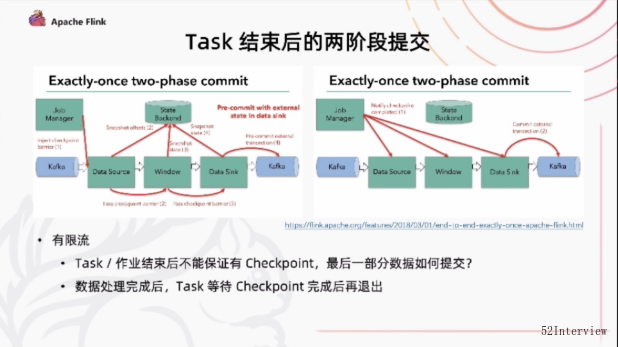
然后另外涉及到的一个问题是我们在有一些sink,比如file sink 这样的一些场景下,可能涉及一些task checkpint 需要两阶段的提交的工作。
具体而言, 在checkpoint 当每一个算子只会进行一次precommit操作 他会把这个数据临时的提交到外部存储。
当所有的任务都完成了这次checkpoint commit之后,它会收到一个信号,这个时候它才会正式提交commit所有的分布式提交的临时文件,一次性的事务式地提交到外部系统。
这种提交方式,在有限流的情况下一部分的任务会提前结束或者说整个作业提前结束之后,并没有后续的Checkpoint。
来进行触发的话,那我们实际上到最后过一段时间执行的任务是很难提交到外部系统。
在flink 1.14 当中,我们也是解决了这样一个问题,我们让task在处理完所有数据以后,必须要等待一次Checkpoint完成,才能够正式地退出。
这是我们在流批一体方面,针对有限流情况下,任务可能会提前结束所做出的这样一些改进。
Checkpoint 机制
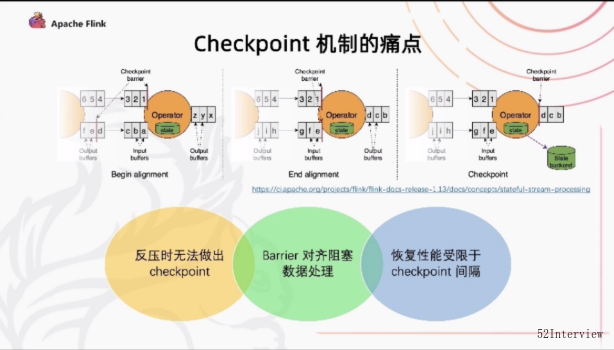
我们先回顾一下flink现有的checkpoint 机制.
实际上我们是靠barrier在算子当中去流通,然后我们在数据当中插入barrier随着数据在算子之间去流,
算子遇到barrier之后,它会把这个状态做一个snap-shot(快照),然后再把barrier往下游继续发送。
对于多路的这种情况,我们可能需要做一个barrier对齐的过程,
会把先到的barrier这一路的数据暂时地block住,然后等到两路的barrier都到了之后,再做这次snap-shot
再会往下去发这个barrier。
那这样的一个现有的checkpoint机制,它有哪些问题呢?
首先,反压的情况下,当我们的数据不能很好地往下游流的时候,barrier也没有办法往下流。
这就造成了我们在反压的情况下做不出checkpoint 而恰恰在很多情况下,在反压的情况下更需要checkpoint 因为在反压的情况下
性能遇到了瓶颈,其实是更容易出问题的一个阶段。
其次, 在多路的输入的算子当中,做这个barrier对齐,可能会阻塞其中一路的数据的处理,这对于性能上是有一定的影响的。
最后,在checkpoint机制作恢复的时候.恢复的性能,业务中断多少,延迟受到多大的影响很大程度上取决于checkpoint 间隔的、
checkpoint的间隔越大,需要reply的数据就越多,从而造成中断的影响就越大。
但是目前的checkpoint的间隔实际上又受制于我们每次做checkpoint对外要做的持久化的操作,所以它没有办法做的很快。
这些都是我们现有flink checkpoint 机制的一些痛点。
- 反压时无法做出checkpoint
- Barrier对齐阻塞数据处理
- 恢复性性能受限于checkpoint间隔
Unaligned Checkpoint
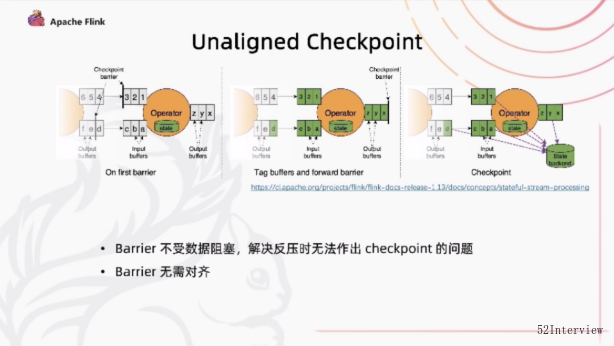
针对以上痛点,flink 1.14, 引入了Unaligned Checkpoint 机制
在Unaligned Checkpoint 机制中,barrier到达算子的整个input buffer 的最前面的时候,我们就会开始触发check point我们会立刻把barrier传到算子的
output buffer的最前面。
这样的话相当于它会立刻地被下游的算子读到,通过这种方式呢,它可以使得barrier不受到数据的阻塞。解决反压的时候,check point 做不出来的
问题。
对于多路的情况,我们会一直等到另一路barrier 到达之前的数据全部都会进行一个标注,通过这种方式 在整个做check point 中也不需要对barrier进行一个对齐。
我们唯一需要做的停顿就是在整个的过程中对buffer和state进行一个标注。
Generalized Incremental
另外一个工作是Generalized Incremental Checkpoint,这个工作的主要目的是为了减少 checkpoint的间隔。
在Incremental Checkpoint中,我们采用的方式是先去让算子写一个state changlog ,写完之后,把这个变化真正地apply到state table上。
state changlog会持续地向一个外部存储进行持久化。在这个过程中,我们不需要等到整个state table 做一个持久化。
我只要保证我对应的checkpoint 的这部分的change log 能够持久化完成就可以开始做下一次的checkpoint。最后state table 是以周期性地方式
独立地去对外做持久化的过程。
这两个过程拆解开之后,从每次checkpoint 都要做全量化state table的持久化操作变成了每次只需要做增量的change log,
然后再加上后台周期性的全量的持久化,我们就可以达到同样的容错的效果。
在这个过程中,每次需要做持久化的数据量减小了,从而是的checkpoint 的间隔做的更加的密集。
对于Unaligned Checkpoint 实际上在flink 1.13就已经发布,而对于Generalized Incremental Checkpoint,目前社区正在做全面地冲刺。
性能与效率
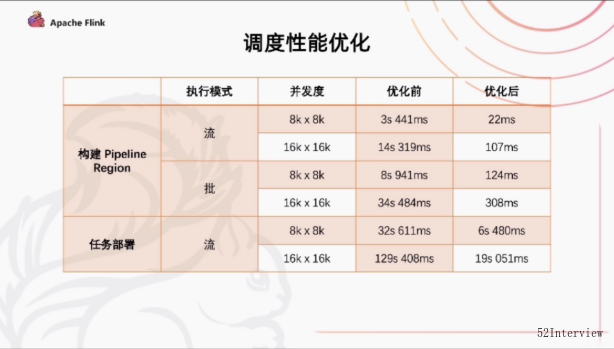
flink 1.13针对比较大规模的作业调度,对flink scheduler 做了一些性能的优化,flink 1.14 也在持续地去做这部分工作。
主要体现在两个方面
第一,在构建pipeline region上面有更好的性能。pipeline region是指所有pipeline的边所连接的节点所构成的子图。我们在flink的任务调度当中需要去通过识别pipeline region来保证同一个有pipeline边所连接的任务能够同时地进行调度,否则就很有可能出现上游调度起来,下游没有起来上游运行完成之后,数据没有办法被下游及时地消费。这种场景可能会造成死锁。
第二,是在任务部署阶段,我们需要去描述每个任务都要从哪个上游去读取数据。这些描述信息我们会生成一个叫Result Partition Depolyment Descriptor 的东西。这样的一个构建的过程。
以上两个方面在flink之前的版本都是有一个O(n²)的时间复杂度,主要是因为我们要对于每一个下游去上游的具体情况,比如遍历读取上游的数据生成Result Partition Depolyment Descriptor。
而现在引入了Group的概念,上下游之间就成了一个OneToOne的连接方式,这就相当于我们把pipeline region,Result Partition Depolyment Descriptor
形成一个group的组合,对于下游只需要知道上游对应的是哪一个group就可以了,把一个O(n²)的时间复杂度优化到了O(n)
我们做了一个简单地测试,用了wordcount 的一个任务,测试结果如下:
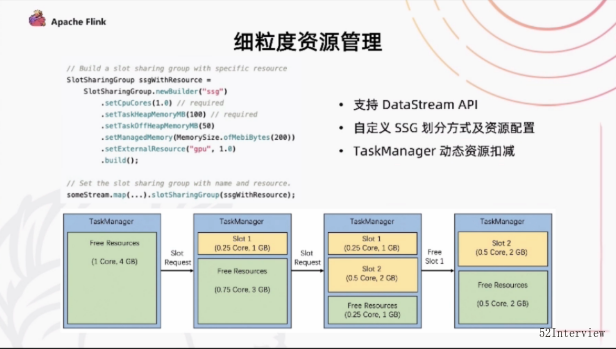
另外一个跟资源调度性能优化相关的是细粒度资源管理,这个工作其实在flink过去的版本一直在做。在这个版本中,我们终于在DataStream上把这个API开放出来,进入到一个可用的阶段。
细粒度资源管理中,用户可以在DataStream的作业中去指定SlotSharingGroup的划分的情况,哪些任务要分到同一个slot当中去执行。
然后,同时我们可以对每一个slot去做一个细致的资源配置。
通过这种方式,我们会自动地根据部署的资源配置进行一个动态的资源切割,不再是每一个taskmanager有固定数量的slot,而是根据资源做一个动态的扣减,通过这种方式,我们也是希望能够达到更好的,更精细的资源管理以及更好的资源使用率。
Table/SQL/Python API
最后给大家带来一些API层面上的一些变化。
Table/SQL
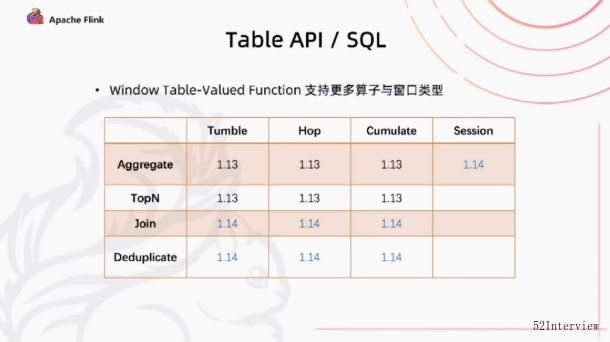
首先,在table api和sql api 当中,widow的表值函数在新的版本中支持了更多算子和窗口类型,增加支持join和Deduplicate操作。
另外,增加了Session类型窗口,目前只能支持Agg的操作。
在table api中可以支持声明式地注册Source/Sink.
table sql 引入了全新的代码生成器,也是因为大家长期以来经常会遇到的一个问题就是生成的java代码会超过这个java代码的最长限制
在新的代码生成器中,会自动地对生成的代码进行拆解,彻底地解决代码超长的问题,
python api
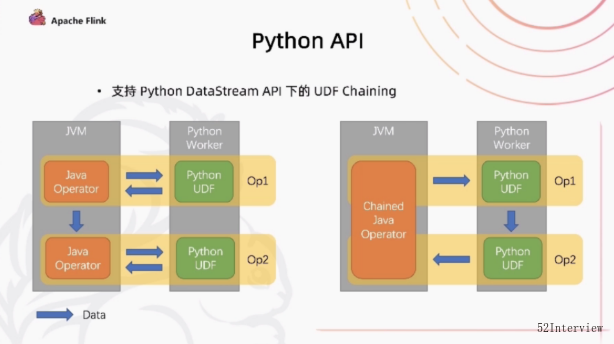
python 方面,我们做的一个很重要的优化是在python的DataStream API 下对UDF的Chaining的一个优化。
在之前的这个版本当中,如果你有先后的两个UDF,先是由Java Operator 把数据发给Python的进程下的UDF执行,执行
完成之后,它又把数据传给下游的Java Operator,然后它又把数据发给另外的Operator,然后再进行一次跨进程之间的
数据处理。这里存在很多次冗余的数据传输。
在现在flink 1.14 版本中,能够很好的把上下游的两个UDF嵌在一起,它们在java当中是共用一个Chained Java Operator,只需要一个来回的Java和Python之间跨进程的通信。那我需要把Java的数据传给Python之后,直接有python的上游的UDF把上游的数据传给下游的UDF,下游处理完之后,再统一的传回Java,这样能够达到一个比较好的性能上的提升。
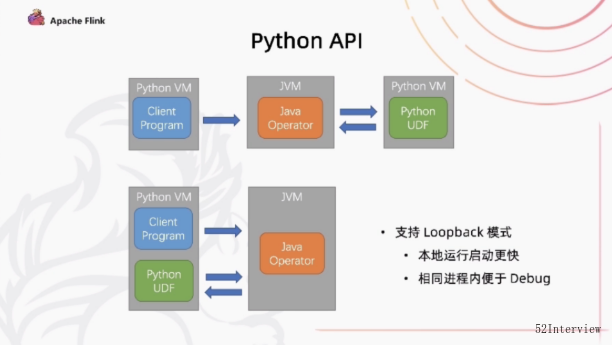
Python做的另外一个工作是对开发者便利的体验上的提升。我们增加了一个支持Loopback模式。
因为在本地执行的时候,我们是在python的进程当中运行Client程序,然后提交一个Java的进程,启一个Cluster去执行Java部分的代码。
然后java部分的代码又会和生产环境上一样,它又去启一个新python进程去执行对应的UDF,这个过程中,新的python进程在本地调试环境是没有必要的。
所以,支持loopback之后,可以让java Operator 直接把UDF运行在之前的python client 所运行的相同的进程内。
通过这种方式,首先我们避免了启动一个额外的进程所带来的开销,另外最重要的是在本地调试的时候,在同一个进程中可以更好地
利用工具进行debug,这是对开发者体验上的提升。