导航
- 微信通讯录
- 尝试利用pinyin4j实现
- 尝试利用JPinyin实现
- 尝试利用pinyin4j-multi实现
- 结语
- 参考
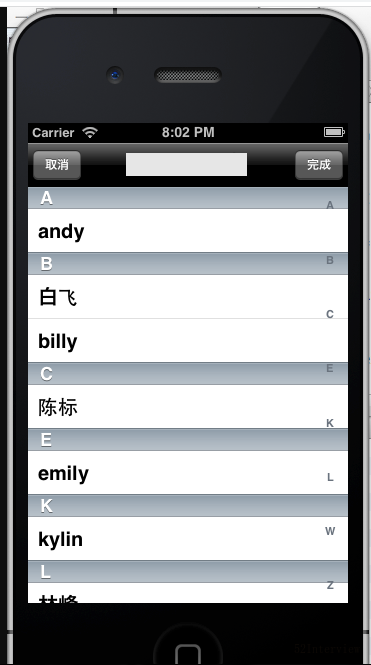
微信通讯录
说道IM,微信是绕不开的话题,毕竟在这个领域微信就是事实上的标杆。
最近,产品经理给我们提了一个功能,内部IM系统增加一个通讯录功能。
规则如下:
- 根据通讯录好友昵称的首字母(或首个汉字拼音首字母)由A-Z排序
- 部分好友昵称是数字或表情符号(比如爱心、气球等等),将会归到#类中
# 排在 A~Z分类之后
咋一看挺简单,毕竟这样的功能大伙儿都很使用过,但是一落实很真不是那么容易。
因为是参照微信的设计,需要对联系人按照首字母排序。而这里的症结是如何准确提取出联系人名字中的拼音首字母。
尝试利用pinyin4j实现
根据规则,我们已经知道,只要能够提取出联系人的拼音首字母,工作就完成一大半了。
项目是基于Springboot框架的,于是很确定的打开google搜索了一把看有没有这样的插件,手气不错,推荐了使用pinyin4j。
pinyin4j支持将汉字转换成拼音,使用也很简单。
<dependency>
<groupId>com.belerweb</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.0</version>
</dependency>
只需要引入这个依赖,就可以直接使用,非常简单。
简单封装了下一下PinYin4jUtils.java
package com.zhike.blogbase.utils;
import java.util.Arrays;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.HanyuPinyinVCharType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
import net.sourceforge.pinyin4j.format.HanyuPinyinVCharType;
import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
import net.sourceforge.pinyin4j.multipinyin.MultiPinyinConfig;
import org.springframework.util.ResourceUtils;
/**
* Copyright (C) 2022 智客工坊(52interview.com)
* The SpringBoot Super-blog Project.
* All rights reserved.
* <p>
* > Github地址: https://github.com/zhikecore/superblog.git
* > 教程地址: https://www.52interview.com/book/36
* > 智客工坊社区:https://www.52interview.com/
* <p>
* 智客工坊(52interview.com) - 经验创造价值,分享成就未来。
* <p>
* PinYin4jUtils at 2022/3/12 22:22,code by JeffreyHu
* You can contact author with zhikecore@foxmail.com.
*/
public class PinYin4jUtils {
/**
* 获取汉字串拼音首字母(第一个字母的首字母),英文字符不变
**/
public static String getFirstSpell(String chinese) {
try {
StringBuffer pybf = new StringBuffer();
char[] arr = chinese.toCharArray();
HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat();
defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
if (arr.length > 0) {
String[] temp = PinyinHelper.toHanyuPinyinStringArray(arr[0], defaultFormat);
if (temp != null) {
pybf.append(temp[0].charAt(0));
}
}
return pybf.toString().replaceAll("\\W", "").trim();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
写了个简单测试,
@Test
void TestGetHeadChar()
{
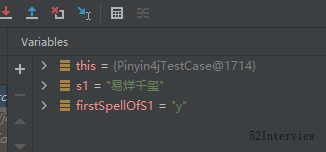
String s1="易烊千玺";
String firstSpellOfS1= PinYin4jUtils.getFirstSpell(s1);
System.out.println(firstSpellOfS1.toUpperCase());
}
查看结果:
看起来一切正常,简单封装一下,功能基本完成。
第二天,对接的前端同学说发现了Bug。我表示一脸懵。
经过仔细排查,原来是遇到了多音字问题。
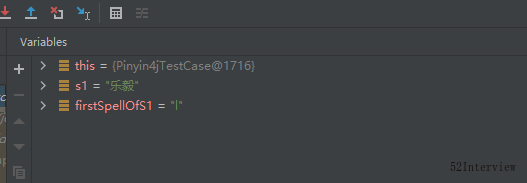
@Test
void TestGetHeadChar()
{
String s1="乐毅";
String firstSpellOfS1= PinYin4jUtils.getFirstSpell(s1);
System.out.println(firstSpellOfS1.toUpperCase());
}
查看结果:
这里,"乐毅"的乐是多音字,在姓氏中应该是"yue",而被识别成"le"。
仔细一想,这插件应该没有那么智能。
由于以前使用过分词插件,猜测pinyin4j应该是有扩展词库吧!
查阅相关资料,发现了这个,
外挂多音词库
用户配置的外挂词库会覆盖系统中相同词的读音,可用于纠错
配置方式很简单,只需要配置路径即可
MultiPinyinConfig.multiPinyinPath="/Users/yiboliu/my_multi_pinyin.txt"
于是,赶紧对代码进行了改造。首先,是在resource目录下增加了/py4j/my_multi_pinyin.txt字典。
然后,在PinYin4jUtils中做了一个扩展词库,
String filePath= "/E:/JavaProjects/superblog/blog-webapp/target/test-classes/py4j/my_multi_pinyin.txt";
MultiPinyinConfig.multiPinyinPath = filePath;
再次,测试"乐毅",依然被识别为"le"。反复尝试,无果。
此路不通,只好放弃该方案。
尝试利用JPinyin实现
本着解决问题的目标,心有不甘,又开始寻找方案。这次,有找到了一个神奇JPinyin。
Pinyin是一个汉字转拼音的Java开源类库,在PinYin4j的功能基础上做了一些改进。
JPinyin主要特性
- 准确、完善的字库;
Unicode编码从4E00-9FA5范围及3007(〇)的20903个汉字中,JPinyin能转换除46个异体字(异体字不存在标准拼音)之外的所有汉字; - 拼音转换速度快;
经测试,转换Unicode编码从4E00-9FA5范围的20902个汉字,JPinyin耗时约100毫秒。 - 多拼音格式输出支持;
JPinyin支持多种拼音输出格式:带音标、不带音标、数字表示音标以及拼音首字母输出格式; - 常见多音字识别;
JPinyin支持常见多音字的识别,其中包括词组、成语、地名等; - 简繁体中文转换
这么好的东西,正中下怀。
在代码中赶紧引入,
<!-- 导入jpinyin -->
<dependency>
<groupId>com.github.stuxuhai</groupId>
<artifactId>jpinyin</artifactId>
<version>1.1.7</version>
</dependency>
写了个测试用例:
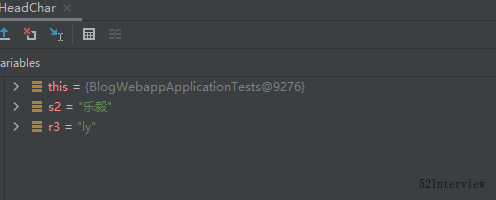
@Test
void TestGetHeadChar()
{
try
{
String s2="乐毅";
String r3= PinyinHelper.getShortPinyin(s2);
System.out.println(r3);
} catch (PinyinException e) {
e.printStackTrace();
}
}
从结果来看,非常稳。
jpinyin确实强大,值得收入囊中。但是,有了前车之鉴,我们不得不保持谨慎。
jpinyin似乎并不支持词库扩展,要是遇到生僻词又该如何是好?
为了确保万无一失,再次开启寻找方案之旅。
尝试利用pinyin4j-multi实现
兜兜转转,还是在pinyin4j附近徘徊。这次,事情有了转机。
pinyin4j-multi是基于pinyin4j的多音字解决方案,并支持词库扩展。
"踏破铁鞋无觅处得来全不费工夫"。我想要的东西终于找到了。
在pinyin4j的基础上添加了多音字识别,带近一万个多音词,但是这远远不够,所以用户可设置外挂词库
在项目中引入pinyin4j插件,
<!--导入pinyin4j-multi-->
<dependency>
<groupId>com.github.obiteaaron</groupId>
<artifactId>pinyin4j-multi</artifactId>
<version>1.0.0</version>
</dependency>
为了验证多音字的支持,我特意找了一个专业词汇——"空调"。
@Test
void TestGetHeadChar() throws Exception {
String s1="空调";
String r1=PinyinHelper.toHanYuPinyinString(s1, outputFormat,";", true);
System.out.println(r1);
}
直接使用,识别结果如下:
很显然,插件成功的步入了下的套。识别错误。
加上外部词库试试,增加空调 (kong1,tiao2)入库,
吸血鬼日记 (xi1,xue4,gui3,ri4,ji4)
重庆 (chong2,qing4)
朝阳站 (chao2,yang2,zhan4)
吴圩机场 (wu2,xu1,ji1,chang3)
长白山 (chang2,bai2,shan1)
空调 (kong1,tiao2)
测试用例,稍加改造:
@Test
void TestGetHeadChar() throws Exception {
String filePath= this.getClass().getResource("/py4j/my_multi_pinyin.txt").getPath();
MultiPinyinConfig.multiPinyinPath = filePath;
String s1="空调";
String r1=PinyinHelper.toHanYuPinyinString(s1, outputFormat,";", true);
System.out.println(r1);
}
启动调试,结果如下:
结果令人满意。暂时就这样吧,真是折腾~
结语
写程序有时候就是这样,充满不确定性。你不得不想做实验一样,一遍一遍地去试错,最后找到一个相对靠谱的解决方案。
通讯录,如此常见的功能,里面也会有不少的潜在逻辑。感谢您的阅读,希望能对您有所帮助~
参考