导航
- 引子
- 棘手的需求
- python request
- 实战案例
- 结语
- 参考
引子
自从用了Python做报表导出,确实给我的工作带来了很多方便。
无论是将数据从excel/csv导入数据库,还是将数据从数据库导出到excel/csv,都能轻松搞定!
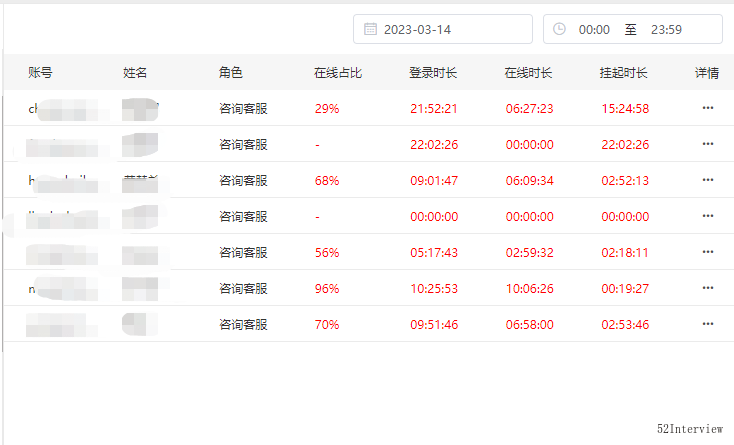
但是,前两天有个女同事找我帮忙导一份她们部门所有人员2月份的在线时长。这着实让我犯了难。
因为这些数据并不是直接从数据库导出,而是在内存中做了复杂计算得出的。我们提供这样的可视化查询界面,但是只能按照天过滤,如果要查看30天的数据,就要筛选三十次。
棘手的需求
面对这样的需求,我以前的那点python储备正式不够用了。是用python从数据库拉取数据,在内存计算,还是直接调用现有接口导出到数据库呢?
思来想去,最终选择了python通过请求现有接口,然后导出数据。
毕竟,这样成本最低。
python request
那么,Python如何请求接口呢?
我们知道Java程序可以通过http请求实现对RestfulApi的请求。在pthon的世界里,我们可以通过python request实现类似的逻辑。
比如,Get和post的示例如下:
r = requests.get('https://api.github.com/events')
r = requests.post('https://httpbin.org/post', data={'key': 'value'})
最通常的方法是通过r=request.get(url)构造一个向服务器请求资源的url对象。这个对象是Request库内部生成的。r返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
关于requests,更多可以查看官方文档:https://docs.python-requests.org/en/latest/user/quickstart/
实战案例
废话不多说,我们现在就用代码来实现上面的需求吧!
import json
import requests
import pymysql
import pymysql.cursors
import xlwt
from datetime import datetime, timedelta
def write_csv(wbk,day,sheet):
try:
url = """http://localhost:8086/api/v1/xxx/on-duty-counselors?deptSourceType=DS&startTime={dtBegin}&endTime={dtEnd}&page=1&limit=50"""
strpattern='%Y-%m-%d %H:%M:%S'
dtBegin0=datetime.strptime('2023-02-01 00:00:00', strpattern)
dtEnd0=datetime.strptime('2023-02-28 23:59:59', strpattern)
dtBegin=(dtBegin0+timedelta(days=day)).strftime(strpattern)
dtEnd=(dtEnd0+timedelta(days=day)).strftime(strpattern)
info = {'dtBegin': dtBegin,'dtEnd':dtEnd}
url = url.format(**info)
print('url:'+url)
res= requests.get(url)
jsonRes=res.json()
result=jsonRes['data']['items']
sheet = wbk.add_sheet(sheet, cell_overwrite_ok=True)
header_row = ["真实姓名","登录时长(秒)", "在线时长(秒)","挂起时长(秒)"]
for i in range(len(result)):
userid=result[i]['userId']
print('userId:'+str(userid))
data = [result[i]['realName'],result[i]['loginTime'],result[i]['onlineTime'],result[i]['hangUpTime']]
if i==0:
for j in range(len(header_row)):
sheet.write(i, j, header_row[j])
for k in range(len(data)):
sheet.write(i+1, k, data[k])
except Exception as e:
print('Error:',e)
finally:
print('执行完成')
if __name__ == '__main__':
wbk = xlwt.Workbook()
for i in range(10):
sheet="03-"+str(i+1)
write_csv(wbk,i,sheet)
wbk.save('on_duty_counselors_month2' + '.xls')
代码中几乎每行都有注释,这里不再赘述。
至此,代码已经编写完成,我们保存为on-duty-counselors.py文件。
接下来,就是让代码run起来,导出到csv。
这里需要注意的是,我们需要提前搭建好python的运行环境。新手同学可以参考《Python安装和使用教程(windows)》。
我这里使用的编辑器是VS Code,推荐您也使用。
上面的代码用VS Code 编辑器打开之后,执行
我们再次执行这个python语句,看看导出结果。
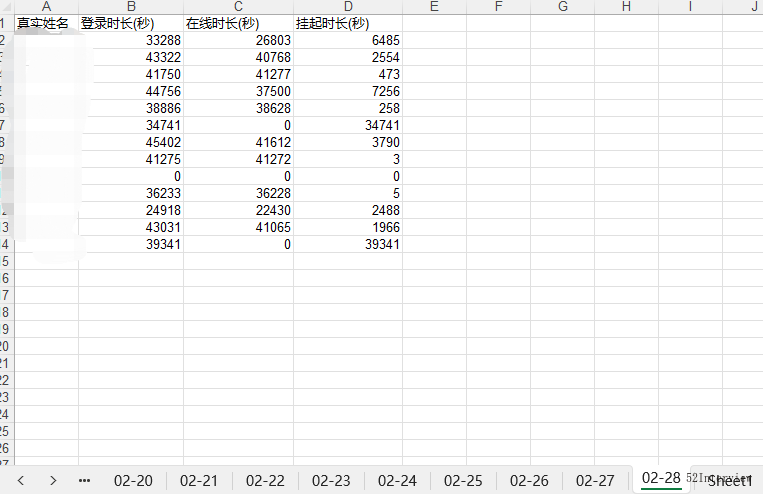
执行之后,生成了一个excel文件。
数据就已经导出成功了,完美!
结语
python对于数据处理具有天然优势,比如它的pandas,非常强大。有兴趣的同学可以进一步研究。
在实际使用过程中,一个文件就可以处理一个报表需求,管理也很方便。
在大数据时代,数据分析已经变得越来越受重视,如果您需要经常需要导出报表或者想成为一名数据分析工程师,那就赶快入手python吧!
参考