centos安装和supervisor管理kafka
导航
- Kafka简介
- java环境配置
- 安装kafka
- 安装kafka服务端
- 测试
- 安装Kafka客户端工具
- 使用supervisor管理kafka服务
- Supervisor是什么
- centos 安装Supervisor
- supervisor管理kafka服务
- 命令行工具模拟生产者消费者
- 常见的kafka操作命令行
- 结语
- 参考
Kafka简介
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka是一款开源的、轻量级的、分布式的、可分区和具有复制备份的(Replicated)、基于ZooKeeper协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,Kafka能够很好地处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
据Kafka官方网站介绍,Kafka定位就是一个分布式流处理平台。
Kafka能够很好地建立实时流式数据通道,由该通道可靠地获取系统或应用程序的数据,也可以通过Kafka方便地构建实时流数据应用来转换或对流式数据进行响应处理。
Kafka的应用已经非常广泛,常见的IM系统、电商网站、推荐系统都有它的身影...
特别是,近年来,在大数据处理中Flink + Kafka的组合逐渐流行起来,让kafka在大数据处理领域也有了更多一展身手的机会。
kafka涉及的知识点较多,其中最重要的是理解生产者-消费者模式,更加具体的概念,可以进一步查阅《官方文档》。
废话不多说,我们赶紧开始搭建kafka的搭建吧!
java环境配置
Kafka运行需要zookeeper配合,而zookeeper需要运行在JVM上,所以需要安装JDK。Kafka 从2.0.0版本开始就不再支持JDK7及以下版本,实际工作中我们一般安装JDK8+。
在Kafka官网下载页面的更新文档中明确指出:
We have dropped support for Java 7 and removed the previously deprecated Scala producer and consumer.--kakfa 2.0.0
操作系统:CentOS 8.2 64bit 云服务器
我们开始配置java环境。
安装jdk
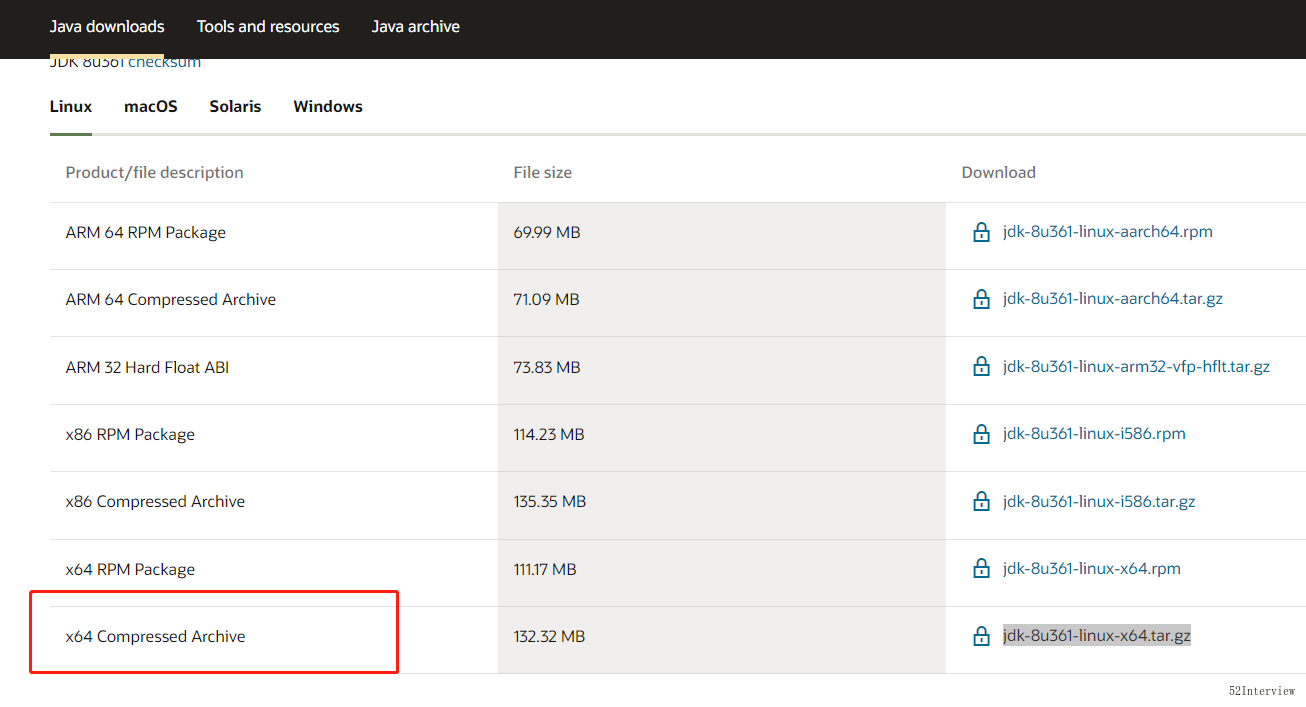
(1) 去Java Downloads | Oracle中下载JDK的安装文件jdk-8u341-linux-x64.tar.gz。
到Oracle官网上Java Downloads中下载JDK的安装文件jdk-8u361-linux-x64.tar.gz,上传到centos上,接着执行本地安装jdk。
(2) 新建/home/java文件夹,将jdk-8u361-linux-x64.tar.gz放到该文件夹下,并切换到/home/java目录下。
(3) 执行命令tar -zxvf jdk-8u361-linux-x64.tar.gz进行解压,解压后/home/java目录下多了jdk1.8.0_361文件夹。
通过以上步骤,JDK安装完毕。
Notes:
a.下载JDK,Oracle官方要求登录,没有账户的请按照说明注册即可。
b.安装jdk有两种方式,一种方式安装oracle jdk得下载安装包,第二种是安装openjdk。OpenJDK只包含最精简的JDK,建议使用第一种方式安装。
配置环境变量
(1) 在/etc/profile.d目录下增加环境变量脚本文件配置JDK环境变量,/etc/profile在每次启动时会执行/etc/profile.d下全部的脚本文件。
在/etc/profile.d目录新建my_env.sh文件,并编辑如下内容:
#JAVA_HOME
export JAVA_HOME=/home/java/jdk1.8.0_361/
export PATH=$PATH:$JAVA_HOME/bin
export CALSSPATH=$CLASSPATH:$JAVA_HOME/lib
#JRE_HOME
export JRE_HOME=/home/java/jdk1.8.0_361/jre/
export PATH=$PATH:$JRE_HOME/bin
export CALSSPATH=$CLASSPATH:$JRE_HOME/lib
(2) 执行如下命令,重载配置文件,让profile文件立即生效
[root@hecs-275297 ~]# source /etc/profile
命令测试
(1) 使用javac命令,不会出现command not found错误
(2) 使用java -version,出现版本为java version "1.8.0_361"
[root@hecs-275297 ~]# java -version
java version "1.8.0_361"
Java(TM) SE Runtime Environment (build 1.8.0_361-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.361-b09, mixed mode)
我们能看到jdk版本已经生效,如果jdk没有安装成功,将会提示-bash: java: command not found
(3) 查看配置是否都正确,echo $JAVA_HOME,echo $CLASSPATH,echo $PATH
[root@hecs-275297 ~]# echo $PATH
/home/java/jdk1.8.0_361//bin:/home/java/jdk1.8.0_361//bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@hecs-275297 ~]# echo $CLASSPATH
.:/home/java/jdk1.8.0_361//lib:/home/java/jdk1.8.0_361//jre/lib
[root@hecs-275297 ~]# echo $PATH
/home/java/jdk1.8.0_361//bin:/home/java/jdk1.8.0_361//bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@hecs-275297 ~]#
特别说明
Centos7系统中配置JDK环境变量的两种方式:
- 修改
/etc/profile文件配置JDK环境变量 - 在
/etc/profile.d目录下增加环境变量脚本文件,配置JDK环境变量
在/etc/profile文件中,也给出了如下说明:
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
不建议在/etc/profile文件中设置系统环境变量,/etc/profile.d比/etc/profile更好管理。
安装kafka
安装指引
(1) 在home目录下新建kafka文件夹,使用wget命令,远程下载kafka_2.13-2.8.2.tgz安装文件
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.2/kafka_2.13-2.8.2.tgz --no-check-certificate
此时,在/home/kafka目录下就会出现名为kafka_2.13-2.8.2.tgz的压缩文件。
Notes: 这里选择国内的清华源,下载速度更快。
(2) 解压文件
进入/home/kafka,将压缩文件解压到当前目录
[root@hecs-275297 ~]# cd /home/kafka/
[root@hecs-275297 kafka]# tar -zxvf kafka_2.13-2.8.2.tgz
kafka_2.13-2.8.2/
kafka_2.13-2.8.2/LICENSE
kafka_2.13-2.8.2/NOTICE
kafka_2.13-2.8.2/bin/
kafka_2.13-2.8.2/bin/kafka-delete-records.sh
...
(3) 修改配置文件
在/home/kafka/kafka_2.13-2.8.2/config/目录下有个server.properties文件。
修改其中的配置:
broker.id=0
log.dir=log.dirs=/tmp/kafka-logs
#配置zookeeper管理kafka的路径
zookeeper.connect=localhost:2181
#配置kafka的监听端口
listeners=PLAINTEXT://:9092
#把kafka的地址端口注册给zookeeper,如果是远程访问要改成外网IP
advertised.listeners=PLAINTEXT://113.116.211.38:9092
Notes: advertised.listeners 以自己的服务器IP地址为准。
(4) 启动
这里采用kafka单机部署模式,修改完上述配置参数之后就可以启动服务。
先启动zookeeper,命令如下:
[root@hecs-275297 ~]# cd /home/kafka/kafka_2.13-2.8.2/
[root@hecs-275297 kafka_2.13-2.8.2]# bin/zookeeper-server-start.sh -daemon config/zookeeper.propertiesbin/zookeeper-server-start.sh
再启动kafka,命令如下:
[root@hecs-275297 kafka_2.13-2.8.2]# bin/kafka-server-start.sh -daemon config/server.properties
测试
通过上面的步骤,我们已经启动了zookeeper和kafka,那么他可以访问了吗?
(1) 创建有测试一个kafka topic
进入到kafka目录下,接着通过下面命令创建一个kafka topic。
[root@hecs-275297 ~]# cd /home/kafka/kafka_2.13-2.8.2/
[root@hecs-275297 kafka_2.13-2.8.2]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
查看创建的topic,可以使用以下命令进行查看
[root@hecs-275297 kafka_2.13-2.8.2]# bin/kafka-topics.sh --list --zookeeper localhost:2181
testTopic
(2) 使用jps命令查看Kafka服务进程是否已经启动,如下:
[root@hecs-275297 kafka_2.13-2.8.2]# jps -l
3945850 kafka.Kafka
1225 org.tanukisoftware.wrapper.WrapperSimpleApp
3945361 org.apache.zookeeper.server.quorum.QuorumPeerMain
3966082 sun.tools.jps.Jps
[root@hecs-275297 kafka_2.13-2.8.2]#
安装Kafka客户端工具
Kafka的应用非常广泛,在实际工作中,往往会查看推送的消息内容,方便排查问题,安装一个kafka可视化工具显得尤为重要,而kafka Tool 就是这样的利器。
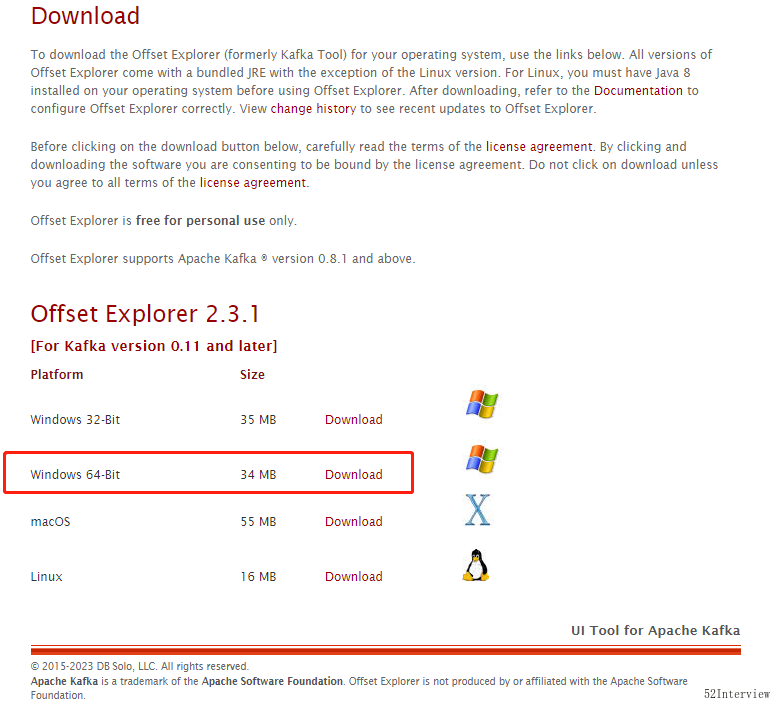
下载kafkatool可以前往官网:https://www.kafkatool.com/download.html
笔者的开发机是Windows 10/11,所以这里选择Windows 64-Bit下载。
选择对应版本,根据提示安装即可。
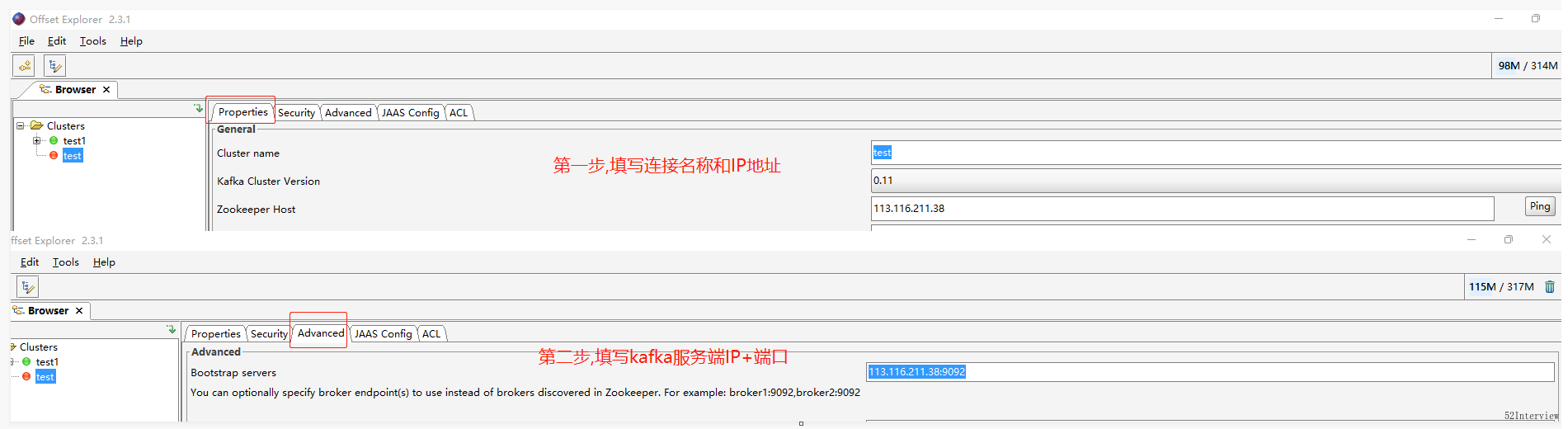
安装之后打开客户端,新建kafka连接
- 填写连接名称和服务器IP地址
- 填写kafka服务器IP+端口
填好之后,保存信息,并连接。连接成功效果如下:
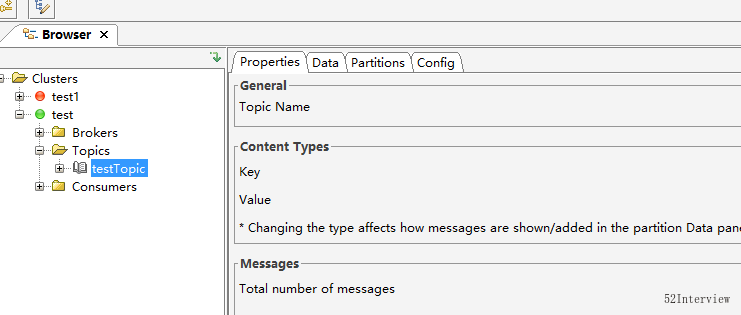
此时,在客户端我们看到了之前在服kafka服务端新建的topic——testTopic。
至此,kafka服务端和客户端的搭建就完成了。
Notes:
a. kafka的服务器IP地址,要以你自己的服务器地址为准
b. 远程连接kafka的服务器的端口,需要开通端口访问权限。
云服务器可以参考《阿里云添加安全组规则》