导航
前言
最近我参与了一个AI效能大赛,主办方希望通过组织这场比赛可以挖掘出更多的AI赋能场景,通过AI为企业降本增效。
过去,技术型公司和技术型同学们总是把技术赋能业务作为口头禅,似乎只有他们才能做这些事情。
然而,随着大模型和AI平台普及和落地,越来越多的懂业务的同学开始关注AI,并开始尝试利用AI解决实际问题。
在这次比赛中,涌现出来很多脑洞打开的应用场景。
比如,有财务同学用Coze工作流实现了电子发票信息的录入系统。
以前人工录入一个电子发票需要10分钟,而且容易出错,现在通过工作流实现了批量上传,批量录入功能,只需要2分钟,这大大提高了工作效率。
受到启发,我也发掘了一下需求场景。
在HR招聘中,很多公司要求求职者提供《教育部学历证书电子注册备案表》,这个文件是教育部学历查询网站(https://www.chsi.com.cn/xlcx/bgcx.jsp)提供的,需要用户登录后才能下载。
这个文件本身是PDF格式的,
HR需要手动下载每个求职者的文件,然后手动录入到Excel中,这个过程非常耗时。
那么,有没有什么办法可以一键读取PDF文件,批量写入Excel呢?
其实,通过AI工作流可以比较简单地实现这样的功能。
今天给大家分享一下,我是如何一步一步搭建工作流的。
欢迎点赞、收藏、关注。
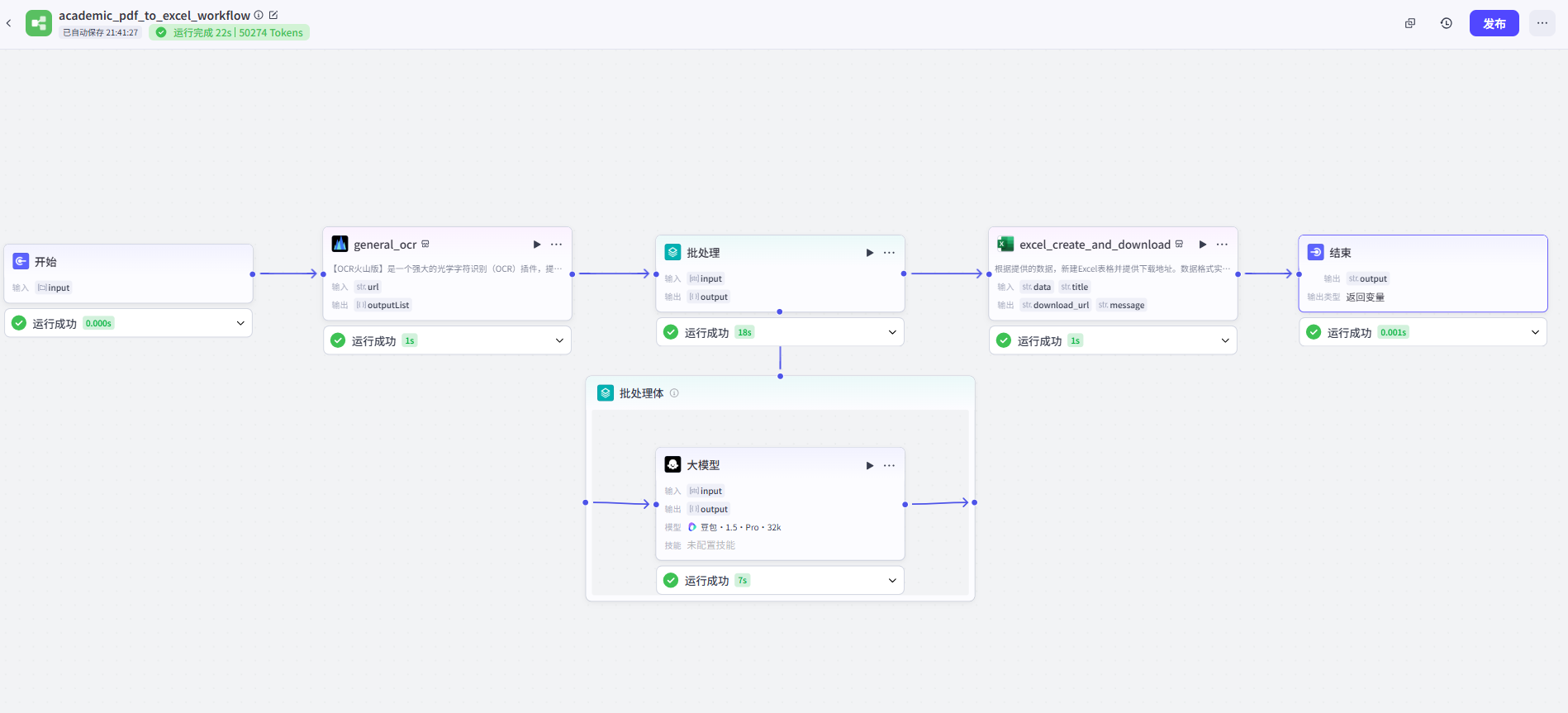
工作流实现效果
工作流程展示
操作步骤
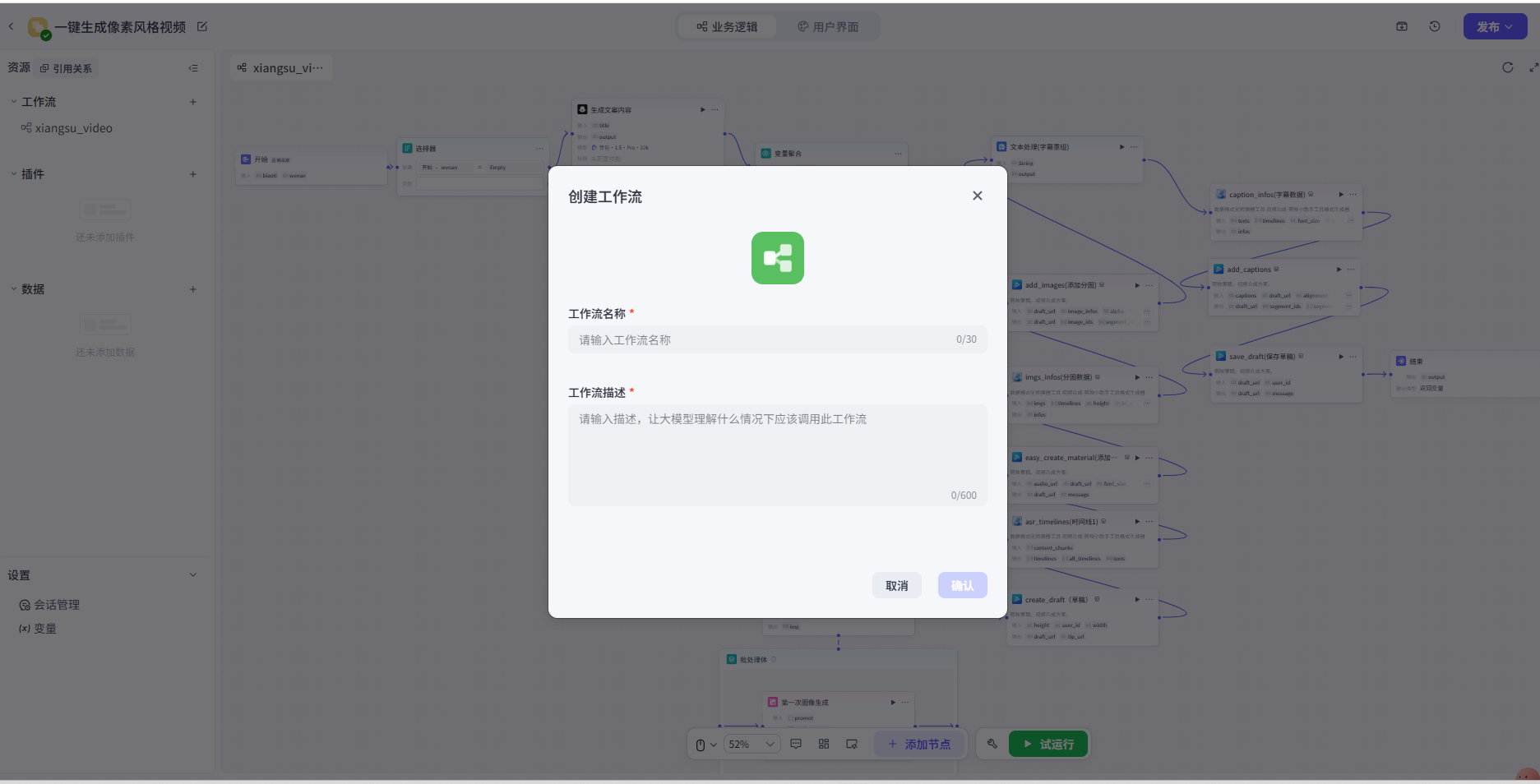
1、创建工作流
登录扣子(coze)平台:https://www.coze.cn/studio
- 选择"开发平台"->"快速开始"
- 在左侧选择"+",选择"创建应用",给应用起一个名称,并选择"确认"
- 在左侧资源库页面右上角单击 +资源,并选择工作流。
- 设置工作流的名称与描述,并单击确认。
如果没有账户,可以先注册一个,coze空间已经全面开开放,免费使用。
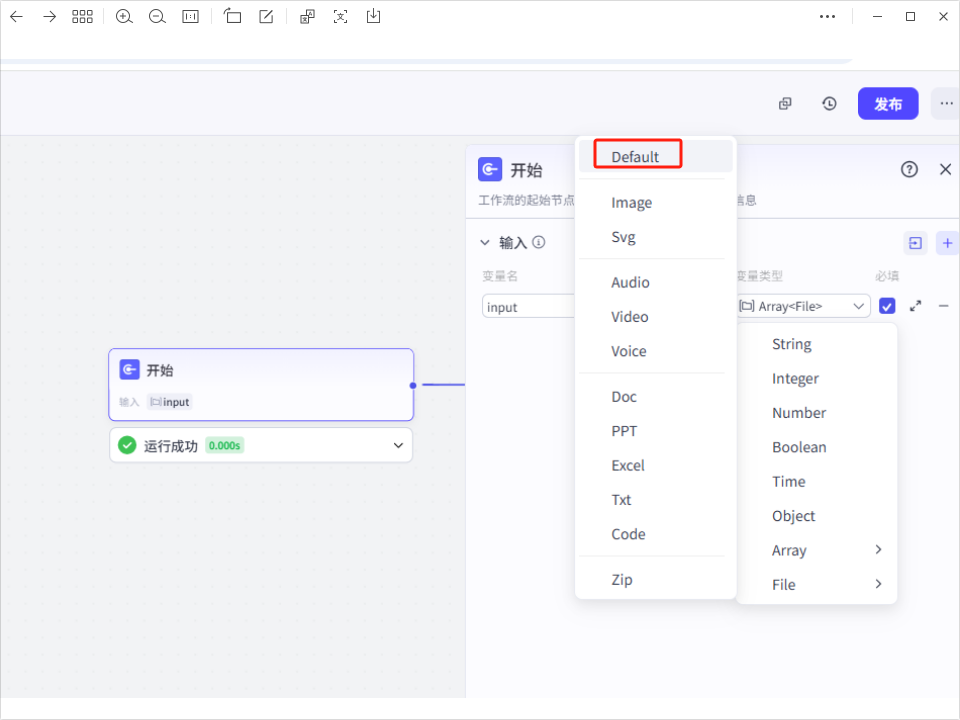
2、开始节点
开始节点,作为入口。
设置一个变量"input",是字符串类型(Array<File>),File选择默认类型,必填。
- input: 输入的文件列表,可以是图片或者pdf文件。
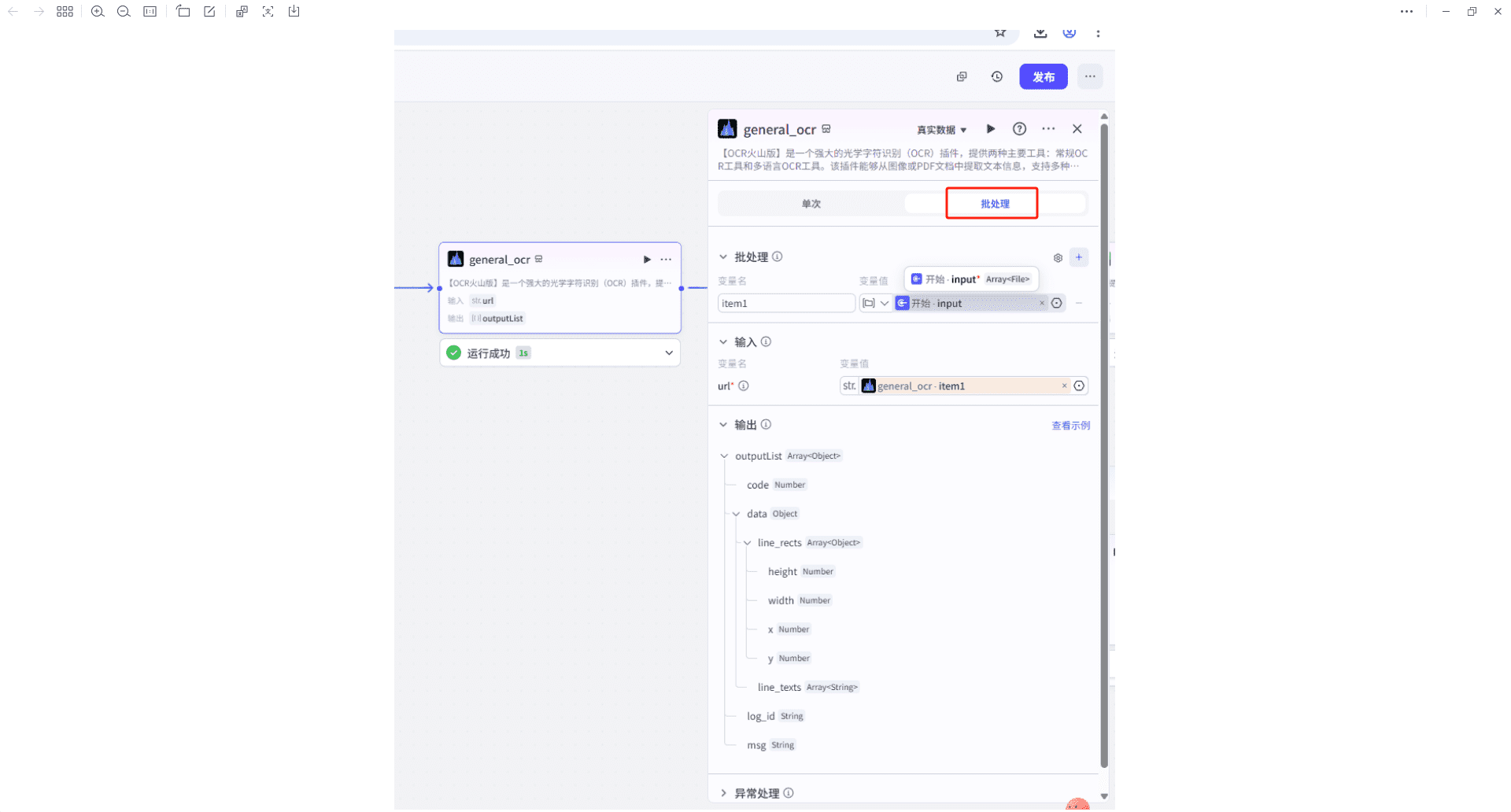
3、general_ocr(OCR插件识别文字)
【OCR火山版】是一个强大的光学字符识别(OCR)插件,提供两种主要工具:常规OCR工具和多语言OCR工具。该插件能够从图像或PDF文档中提取文本信息,支持多种语言,适用于各种应用场景。
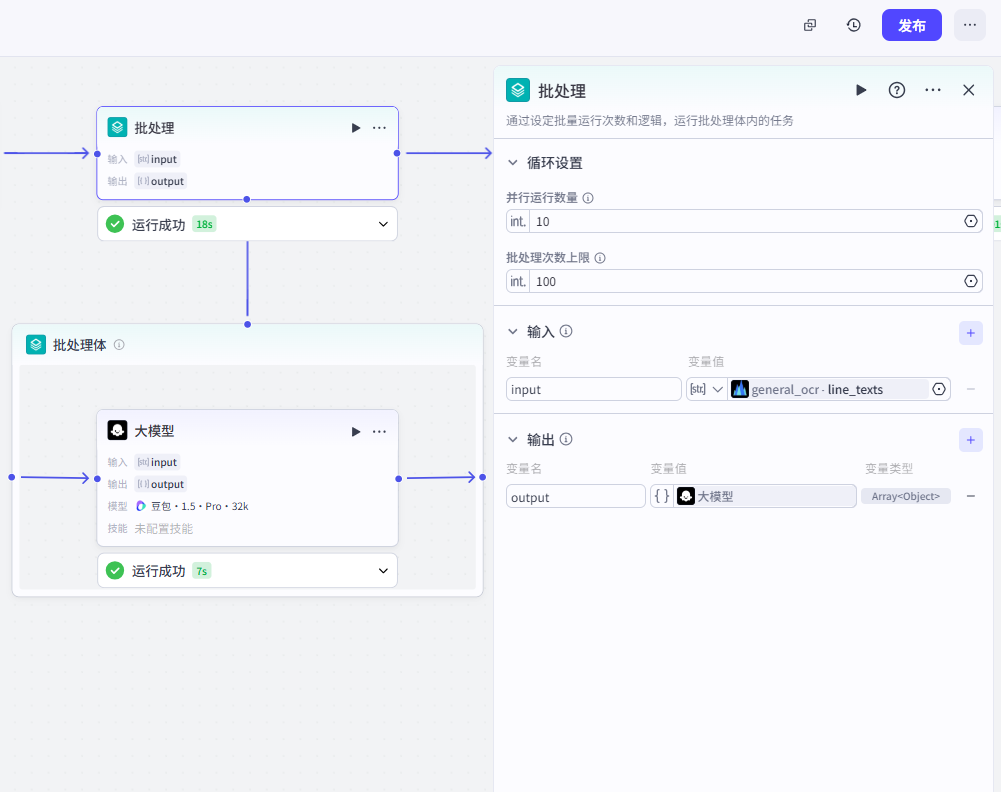
在“开始节点”允许上传多个文件,所以OCR也要支持批量识别,这里选择”批处理“模式。
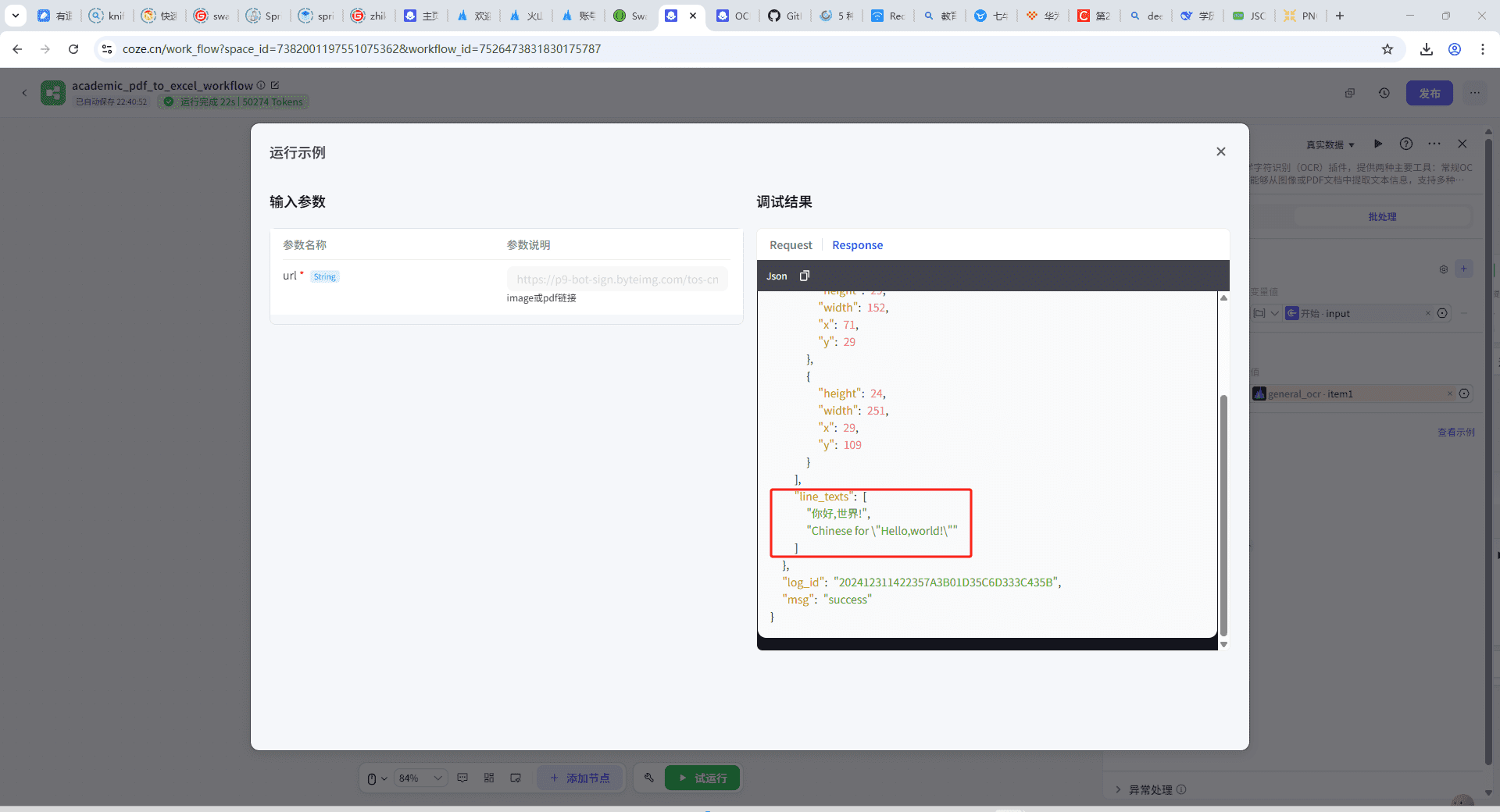
插入输出结构如下:
"line_texts"字段中就是识别出的内容,是数组结构。
4、批处理提取学历信息