2.2 K 近邻算法和距离度量介绍
简介
K-近邻算法,又名最近邻居算法,其英文缩写是KNN(k-nearest neighbors)。是一种用于分类和回归的非参数统计方法。其可能是标准数据挖掘算法中最为直观的一种。本篇,主要讨论knn用于分类的情况。
在分类中,为了确定新的个体属于哪一个类,就寻找训练集,查找与新个体最为相似的个体,然后根据查找到的大多数个体属于哪一个类别,就将这个个体分类到这个类别中。
一下面这张图为例子,我们如何判断绿色的个体属于哪一个类别?首先我们寻找与绿色点距离(欧式距离)最近的三个($K=3$)个体——2个三角形,1个正方形。三角形多于正方形,此时我们就认为该个体属于三角形。
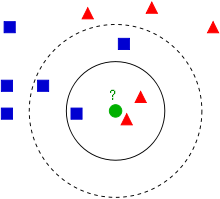
近邻算法几乎可以对任何数据集进行分类。原理也很简单,实现也简单,但是计算量却比较大,因为他需要对所有的点计算距离。
在上面的举例中,有两个关键点需要我们注意:
- K的取值
- 距离的计算
K的取值可以简单理解为他决定着我们需要考虑多少个“邻居”,而这个就会影响我们的模型的准确度!
那么距离的计算是什么呢?在前面的例子中,我们的距离指的是两个点连成直线的距离(亦称欧氏距离),距离越短则代表两者之间越亲密,但是欧式距离越短一定就越近吗?想一想重庆的山城。

OK,接下来让我们来讲一讲距离度量。
距离度量
距离是数据挖掘的核心概念之一。因为我们可以通过距离来判断一对个体相对另一对个体是否更加的相近。距离的计算有很多种方式,接下来,将介绍几种常见的计算方式。
欧式距离
欧式距离是我们接触过最多的一种度量方式,即真实距离。
以下图为例,我们如何计算A,B之间的欧式距离?
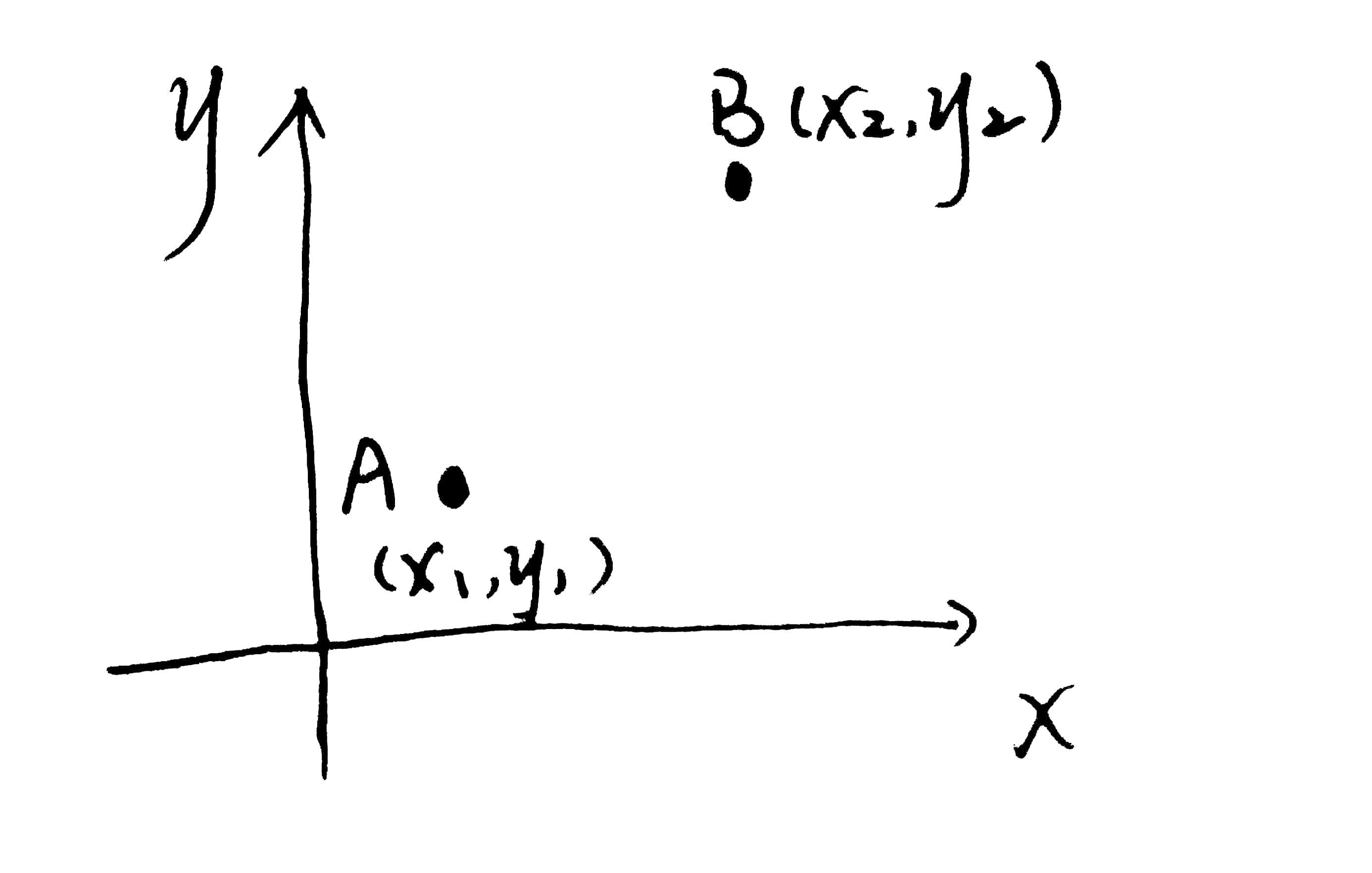
emm,这个很简单,初中的时候就学过了。
上面的公式是二维坐标系情况下的计算的公式,如果是n维坐标系呢?
$A_k$代表A点在k轴的位置.
我们可以将欧式距离进行标准化:
$A_k$代表A点在k轴的位置,其中,$s_k$为数据每一维的标准差,之所以这样做,是因为考虑到了坐标轴中维度的不同。比如说$x$轴的范围是0~1,但是$y$轴的范围是0~100,这样就会造成$x,y$轴的权重不同,而是用标准化就可以解决这个问题。
曼哈顿距离
曼哈顿距离也称为街区距离,如果拿国际象棋来说,A到B的距离就是A作为車,A到B需要走多少距离。
如下图所示,白色的圈圈到黑色的圈圈需要的距离用红色的线进行表示。

计算距离的公式如下所示。
$k$代表的是$k$维坐标系,$A_k$代表$A$点在$k$轴的位置
余弦定理
余弦距离指的是特征向量之间的夹角的余弦值,如下图红色部分所示:

至于怎么计算,感觉又回到了高中~.~

$\because \overrightarrow {a} \cdot \overrightarrow{b} = |a|\times|b|\times cos\theta \ \therefore cos\theta = \frac{\overrightarrow {a} \cdot \overrightarrow{b}}{|a|\times |b|}= \dfrac{\Sigma_{k=1}^n a_k b_k}{\sqrt{\Sigma_{k=1}^n a_k^2} \sqrt{\Sigma_{k=1}^n b_k^2}}$
本篇主要是讲一下近邻算法以及距离的计算方式。在下一篇博客中,将使用scikit-learn,以KNN为例进行数据挖掘。
距离的度量暂时先说到这里,以后会继续进行添加修正。
参考
- 《Python数据挖掘入门与实践》






