2.6 列表
Redis的列表相当于Java语⾔⾥⾯的LinkedList,数据结构形式为链表,插⼊和删除操作⾮常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n)。
当列表弹出了最后⼀个元素之后,该数据结构⾃动被删除,内存被回收。
插入元素后,各元素的相对位置确定,遍历的结果也与之保持一致。链表元素可以重复。下面我们看看它的API
1.LPUSH¶
LPUSH key value [value …]
时间复杂度:O(1)
将一个或多个值value插入到列表key的表头。如果有多个value值,那么各个value值按从左到右的顺序依次插入到表头:比如说,对空列表mylist执行命令LPUSH mylist a b c,列表的值将是c b a ,这等同于原子性地执行LPUSH mylist a 、 LPUSH mylist b 和LPUSH mylist c 三个命令。如果key不存在,一个空列表会被创建并执行LPUSH操作。当key存在但不是列表类型时,返回一个错误。正常返回列表的长度。
# 加入单个元素 redis> LPUSH languages python (integer) 1 # 加入重复元素 redis> LPUSH languages python (integer) 2 redis> LRANGE languages 0 -1 # 列表允许重复元素 1) "python" 2) "python" # 加入多个元素 redis> LPUSH mylist a b c (integer) 3 redis> LRANGE mylist 0 -1 1) "c" 2) "b" 3) "a"
2.RPUSH¶
RPUSH key value [value …]
时间复杂度:O(1)
将一个或多个值value插入到列表key的表尾(最右边)。如果有多个value 值,那么各个value值按从左到右的顺序依次插入到表尾:比如对一个空列表mylist 执行 RPUSH mylist a b c,得出的结果列表为 a b c,等同于执行命令RPUSH mylist a 、 RPUSH mylist b 、 RPUSH mylist c 。如果key不存在,一个空列表会被创建并执行RPUSH操作。当key存在但不是列表类型时,返回一个错误。正常返回列表的长度。
# 添加单个元素 redis> RPUSH languages c (integer) 1 # 添加重复元素 redis> RPUSH languages c (integer) 2 redis> LRANGE languages 0 -1 # 列表允许重复元素 1) "c" 2) "c" # 添加多个元素 redis> RPUSH mylist a b c (integer) 3 redis> LRANGE mylist 0 -1 1) "a" 2) "b" 3) "c"
3.LINSERT¶
LINSERT key BEFORE|AFTER pivot value
时间复杂度:O(N),N为寻找pivot过程中经过的元素数量。
将值value插入到列表key当中,位于值pivot之前或之后。当pivot不存在于列表key时,不执行任何操作。当key不存在时,key被视为空列表,不执行任何操作。如果key不是列表类型,返回一个错误。如果命令执行成功,返回插入操作完成之后,列表的长度。如果没有找到pivot,返回-1。如果 key不存在或为空列表,返回0。
redis> RPUSH mylist "Hello" (integer) 1 redis> RPUSH mylist "World" (integer) 2 redis> LINSERT mylist BEFORE "World" "There" (integer) 3 redis> LRANGE mylist 0 -1 1) "Hello" 2) "There" 3) "World" # 对一个非空列表插入,查找一个不存在的 pivot redis> LINSERT mylist BEFORE "go" "let's" (integer) -1 # 失败 # 对一个空列表执行 LINSERT 命令 redis> EXISTS fake_list (integer) 0 redis> LINSERT fake_list BEFORE "nono" "gogogog" (integer) 0 # 失败
4.LPOP¶
LPOP key
时间复杂度:O(1)
移除并返回列表key的头元素。返回列表的头元素。当key不存在时,返回nil。
redis> LLEN course (integer) 0 redis> RPUSH course algorithm001 (integer) 1 redis> RPUSH course c++101 (integer) 2 redis> LPOP course # 移除头元素 "algorithm001"
5.RPOP¶
RPOP key
时间复杂度:O(1)
移除并返回列表key的尾元素。返回列表的尾元素。当key不存在时,返回 nil。
redis> RPUSH mylist "one" (integer) 1 redis> RPUSH mylist "two" (integer) 2 redis> RPUSH mylist "three" (integer) 3 redis> RPOP mylist # 返回被弹出的元素 "three" redis> LRANGE mylist 0 -1 # 列表剩下的元素 1) "one" 2) "two"
6.LREM¶
LREM key count value
时间复杂度:O(N),N为列表的长度。
根据参数count的值,移除列表中与参数value相等的元素。
count的值可以是以下几种: - count > 0:从表头开始向表尾搜索,移除与value相等的元素,数量为count。 - count < 0:从表尾开始向表头搜索,移除与value相等的元素,数量为count的绝对值。 - count = 0:移除表中所有与value相等的值。
返回值被移除元素的数量。因为不存在的key被视作空表(empty list),所以当key 不存在时,LREM命令总是返回0。
# 先创建一个表,内容排列是 # morning hello morning helllo morning redis> LPUSH greet "morning" (integer) 1 redis> LPUSH greet "hello" (integer) 2 redis> LPUSH greet "morning" (integer) 3 redis> LPUSH greet "hello" (integer) 4 redis> LPUSH greet "morning" (integer) 5 redis> LRANGE greet 0 4 # 查看所有元素 1) "morning" 2) "hello" 3) "morning" 4) "hello" 5) "morning" redis> LREM greet 2 morning # 移除从表头到表尾,最先发现的两个 morning (integer) 2 # 两个元素被移除 redis> LLEN greet # 还剩 3 个元素 (integer) 3 redis> LRANGE greet 0 2 1) "hello" 2) "hello" 3) "morning" redis> LREM greet -1 morning # 移除从表尾到表头,第一个 morning (integer) 1 redis> LLEN greet # 剩下两个元素 (integer) 2 redis> LRANGE greet 0 1 1) "hello" 2) "hello" redis> LREM greet 0 hello # 移除表中所有 hello (integer) 2 # 两个 hello 被移除 redis> LLEN greet (integer) 0
7.LTRIM¶
LTRIM key start stop
时间复杂度:O(N),N为被移除的元素的数量。
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
这个从字面意思不容易理解,我们图解一下:
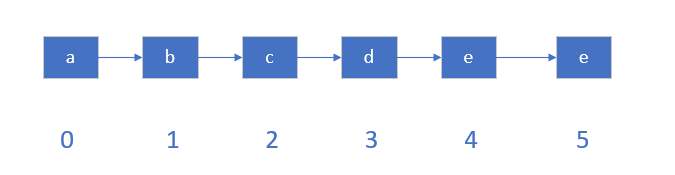
运行命令
Ltrim listkey 1 4
结果
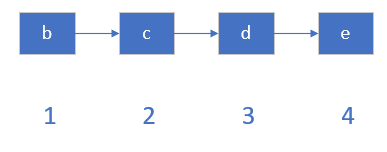
上面的图能一下子让你看懂,它是做什么的了,下面演示一下
# 情况 1: 常见情况, start 和 stop 都在列表的索引范围之内 redis> LRANGE alpha 0 -1 # alpha 是一个包含 5 个字符串的列表 1) "h" 2) "e" 3) "l" 4) "l" 5) "o" redis> LTRIM alpha 1 -1 # 删除 alpha 列表索引为 0 的元素 OK redis> LRANGE alpha 0 -1 # "h" 被删除了 1) "e" 2) "l" 3) "l" 4) "o" # 情况 2: stop 比列表的最大下标还要大 redis> LTRIM alpha 1 10086 # 保留 alpha 列表索引 1 至索引 10086 上的元素 OK redis> LRANGE alpha 0 -1 # 只有索引 0 上的元素 "e" 被删除了,其他元素还在 1) "l" 2) "l" 3) "o" # 情况 3: start 和 stop 都比列表的最大下标要大,并且 start < stop redis> LTRIM alpha 10086 123321 OK redis> LRANGE alpha 0 -1 # 列表被清空 (empty list or set) # 情况 4: start 和 stop 都比列表的最大下标要大,并且 start > stop redis> RPUSH new-alpha "h" "e" "l" "l" "o" # 重新建立一个新列表 (integer) 5 redis> LRANGE new-alpha 0 -1 1) "h" 2) "e" 3) "l" 4) "l" 5) "o" redis> LTRIM new-alpha 123321 10086 # 执行 LTRIM OK redis> LRANGE new-alpha 0 -1 # 同样被清空 (empty list or set)
8.LINDEX¶
LINDEX key index
时间复杂度:O(N),N为到达下标index过程中经过的元素数量。因此,对列表的头元素和尾元素执行LINDEX命令,复杂度为O(1)。
返回列表key中,下标为index的元素。下标(index)参数start和stop都以0为底,也就是说,以0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。你也可以使用负数下标,以 -1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。如果key不是列表类型,返回一个错误。返回列表中下标为index的元素。如果index参数的值不在列表的区间范围内(out of range),返回 nil。
redis> LPUSH mylist "World" (integer) 1 redis> LPUSH mylist "Hello" (integer) 2 redis> LINDEX mylist 0 "Hello" redis> LINDEX mylist -1 "World" redis> LINDEX mylist 3 # index不在 mylist 的区间范围内 (nil)
9.LLEN¶
LLEN key
时间复杂度:O(1)
返回列表key的长度。如果key不存在,则key被解释为一个空列表,返回0。如果key不是列表类型,返回一个错误。
# 空列表 redis> LLEN job (integer) 0 # 非空列表 redis> LPUSH job "cook food" (integer) 1 redis> LPUSH job "have lunch" (integer) 2 redis> LLEN job (integer) 2
10.LSET¶
LSET key index value
时间复杂度:对头元素或尾元素进行LSET操作,复杂度为O(1)。其他情况下,为O(N),N 为列表的长度。
将列表key下标为index的元素的值设置为value。当index参数超出范围,或对一个空列表(key 不存在)进行LSET时,返回一个错误。操作成功返回ok,否则返回错误信息。
# 对空列表(key 不存在)进行 LSET redis> EXISTS list (integer) 0 redis> LSET list 0 item (error) ERR no such key # 对非空列表进行 LSET redis> LPUSH job "cook food" (integer) 1 redis> LRANGE job 0 0 1) "cook food" redis> LSET job 0 "play game" OK redis> LRANGE job 0 0 1) "play game" # index 超出范围 redis> LLEN list # 列表长度为 1 (integer) 1 redis> LSET list 3 'out of range' (error) ERR index out of range
下面我们看一下它的应用:
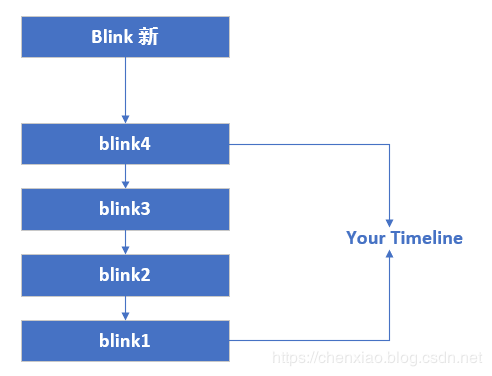
最典型的就是时间轴。以CSDN APP的bink推荐为例,
当有一个bink发表的时候,要将这个blink插入时间轴第一个位置。可以是LPUSH的操作。这样子每次你就能从列表中,看到最新的blink,越往下时间越远。
11. BLPOP¶
BLPOP key [key …] timeout
时间复杂度:O(1)
BLPOP是列表的阻塞式(blocking)弹出原语。它是LPOP key 命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被BLPOP命令阻塞,直到等待超时或发现可弹出元素为止。当给定多个key参数时,按参数key的先后顺序依次检查各个列表,弹出第一个非空列表的头元素。
12.BRPOP¶
BRPOP key [key …] timeout 时间复杂度:O(1)
BRPOP是列表的阻塞式(blocking)弹出原语。它是RPOP key命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被BRPOP命令阻塞,直到等待超时或发现可弹出元素为止。当给定多个key参数时,按参数key的先后顺序依次检查各个列表,弹出第一个非空列表的尾部元素。
下面再看一个Redis的应用:简易的消息队列
Redis的简易的消息队列不是专业的消息队列,它没有⾮常多的⾼级特性,没有ack保证,如果对消息的可靠性有着极致的追求,那么它就不适合使⽤。但是对于那些只有⼀组消费者的消息队列,使⽤Redis就可以⾮常轻松的搞定。
后面会谈到Redis的高级特性–发布订阅。这个也是消息队列
异步消息队列¶
Redis的list(列表)数据结构常⽤来作为异步消息队列使⽤,使⽤rpush/lpush操作⼊队列,使⽤lpop和rpop来出队列。
客户端是通过队列的pop操作来获取消息,然后进⾏处理。处理完了再接着获取消息,再进⾏处理。如此循环往复。
但是如果队列空了,客户端就会陷⼊pop的死循环,不停地pop。这样不但拉⾼了客户端的CPU,redis的QPS(每秒执行次数)也会被拉⾼,如果这样不断轮询的客户端有⼏⼗来个,资源被大量无效占用。通常我们使⽤sleep来解决这个问题,让线程睡⼀会,睡个1s钟就可以了。不但客户端的 CPU能降下来,Redis的QPS也降下来了。不过这样也并不是很好的手段。
延时队列¶
运用blpop/brpop构建延时队列是一个非常好的方式。这两个指令的前缀字符b代表的是blocking,也就是阻塞读。
阻塞读在队列没有数据的时候,会⽴即进⼊休眠状态,⼀旦数据到来,则⽴刻醒过来。消息的延迟⼏乎为零。不过这也带来一个问题:空闲连接。如果线程⼀直阻塞在哪⾥,Redis的客户端连接就成了闲置连接,闲置过久,服务器⼀般会主动断开连接,减少闲置资源占⽤。这个时候blpop/brpop会抛出异常来。编写客户端消费者的时候要⼩⼼,注意捕获异常,还要重试。
在上面简单说明分布式锁的时候,没有提到客户端在处理请求时加锁没加成功怎么办。对于这种情况,有3种策略来处理加锁失败:
- 直接抛出异常,通知⽤户稍后重试;
- sleep⼀会再重试;
- 将请求转移⾄延时队列,过⼀会再试;






