4.2 pipeline
pipeline的中文意思是管道。
下面通过图示,我们看看认清楚什么是流水线。
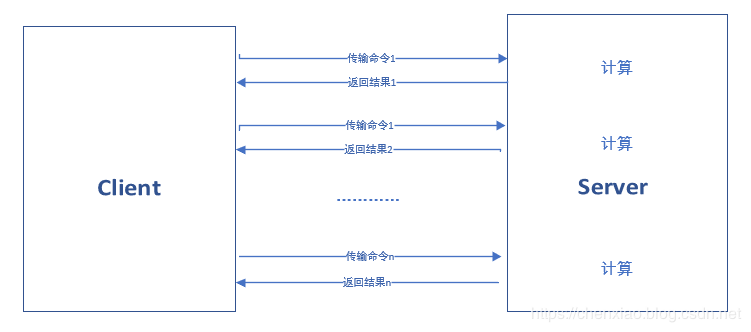
批量网络命令通信模型:n次时间=n次网络时间+n次命令时间
Pipeline模型:
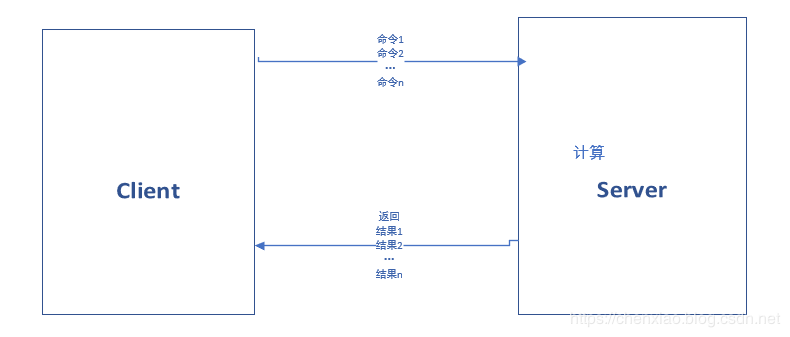
pipeline就是把一批命令进行打包,然后传输给server端进行批量计算,然后按顺序将执行结果返回给client端使用Pipeline模型进行n次网络通信需要的时间:
1次pipeline(n条命令) = 1次网络时间 + n次命令时间
为了更具体,我们可以测试一下时间:(python实现)
import redis
import time
client = redis.StrictRedis(host='192.168.81.100',port=6379)
start_time = time.time()
for i in range(10000):
client.hset('hashkey','field%d' % i,'value%d' % i)
ctime = time.time()
print(client.hlen('hashkey'))
print(ctime - start_time)
程序执行结果:
10000 2.0011684894561768
在上面的例子里,直接向Redis中写入10000条hash记录,需要的时间大约为2.00秒,使用pipeline的方式向Redis中写入1万条hash记录
import redis
import time
client = redis.StrictRedis(host='192.168.81.100',port=6379)
start_time = time.time()
for i in range(100):
pipeline = client.pipeline()
j = i * 100
while j < (i+ 1) * 100:
pipeline.hset('hashkey1','field%d' % j * 100,'value%d' % i)
j += 1
pipeline.execute()
ctime = time.time()
print(client.hlen('hashkey1'))
print(ctime - start_time)
程序执行结果:
10000 0.3175079822540283
可以看到使用Pipeline方式每次向Redis服务端发送100条命令,发送100次所需要的时间仅为0.31秒,可以看到使用Pipeline可以节省网络传输时间
值得注意的是:
- 每次pipeline携带数据量不能太大
- pipeline可以提高Redis批量处理的并发的能力,但是并不能无节制的使用
- 如果批量执行的命令数量过大,则很容易对网络及客户端造成很大影响,此时可以把命令分割,每次发送少量的命令到服务端执行
- pipeline每次只能作用在一个Redis节点上
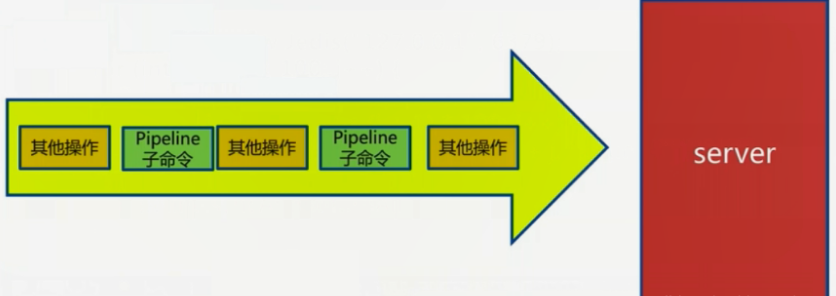
还有,记得pipeline命令不是原子命令(要么全部一下子执行,要么不执行),pipeline中命令以子命令的形式穿插在Redis执行的其他命令当中

版权声明:
本文为智客工坊「沉晓」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。





