1.2 主流消息中间件介绍——Kafka
Apache Kafka是一个分布式消息发布订阅系统。
它最初由LinkedIn公司基于独特的设计实现为一个分布式的日志提交系统(a distributed commit log),之后成为Apache项目的一部分。Kafka性能高效、可扩展良好并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
1 特点

kafka是LinkedIn开源的分布式发布-定于消息系统,目前归属于Apache顶级项目。
Kafka主要特点是给予Pull的模式来处理消费消息,追求高吞吐量,一开始的目的就是用于日志收集和传输。
0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。这里可以看出kafka只关注吞吐量。
因此,在使用kafka的时候,注意业务是否允许消息重复、丢失、错误等。如果允许的话,kafka是最合适的。因为它的性能是最高的。即使在廉价的服务器上,也能支持单机每秒100k条以上的数据量。所以说它的性能是非常好的。kafka仅仅使用内存进行存储,只要有足够的内存,就能够足够大的吞吐量。因为kafka并没有在磁盘上进行读写。
- 快速持久化:可以在O(1)的系统开销下进行消息持久化;
- 高吞吐:在一台普通的服务器上既可以达到10W/s的吞吐速率;
- 完全的分布式系统:Broker、Producer和Consumer都原生自动支持分布式,自动实现负载均衡;
- 支持同步和异步复制两种高可用机制;
- 支持数据批量发送和拉取;
- 零拷贝技术(zero-copy):减少IO操作步骤,提高系统吞吐量;
- 数据迁移、扩容对用户透明;
- 无需停机即可扩展机器;
- 其他特性:丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制
2 kafka架构模式
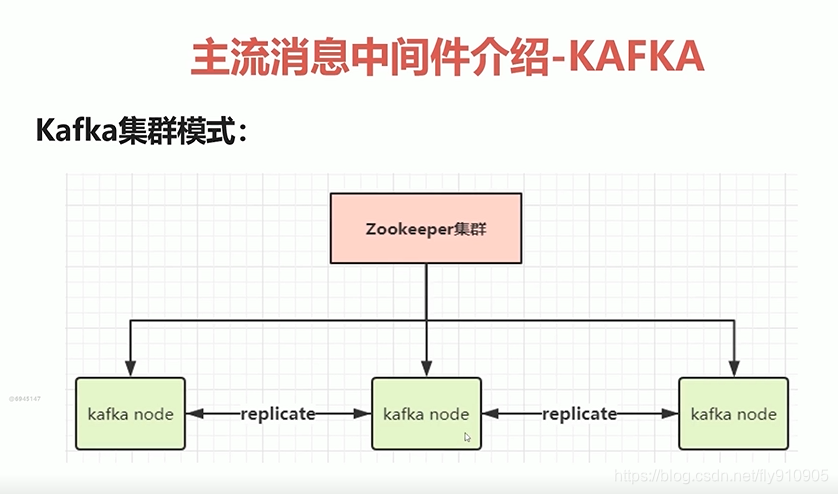
主要依赖Zookeeper进行协调管理,每一个kafka可以进行副本复制,也就是数据同步。
假如说:有一条数据落在第一个节点上,那么就会进行repilicate 复制,这样在运行中每个节点就有一份数据,一共就有三分数据。如果说其中一台宕机,也能从另外两个节点中获取数据。
部署方案建议:跨机房部署。即使有一台机子宕机,在数据上也是没有问题的。如果在整个地点宕机了。那么我们的数据也就丢失了。这也是大公司需要考虑的异地灾备。当然kafka主要关注性能的,对于数据的可靠性关注并高。
3 kafka小结
kafka优点:
- 客户端语言丰富:支持Java、.Net、PHP、Ruby、Python、Go等多种语言;
- 高性能:单机写入TPS约在100万条/秒,消息大小10个字节;
- 提供完全分布式架构,并有replica机制,拥有较高的可用性和可靠性,理论上支持消息无限堆积;
- 支持批量操作;
- 消费者采用Pull方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方KafkaWeb管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用。
kafka缺点:
- Kafka单机超过64个队列/分区时,Load时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长;
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢。

版权声明:
本文为智客工坊「琦彦 」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。





